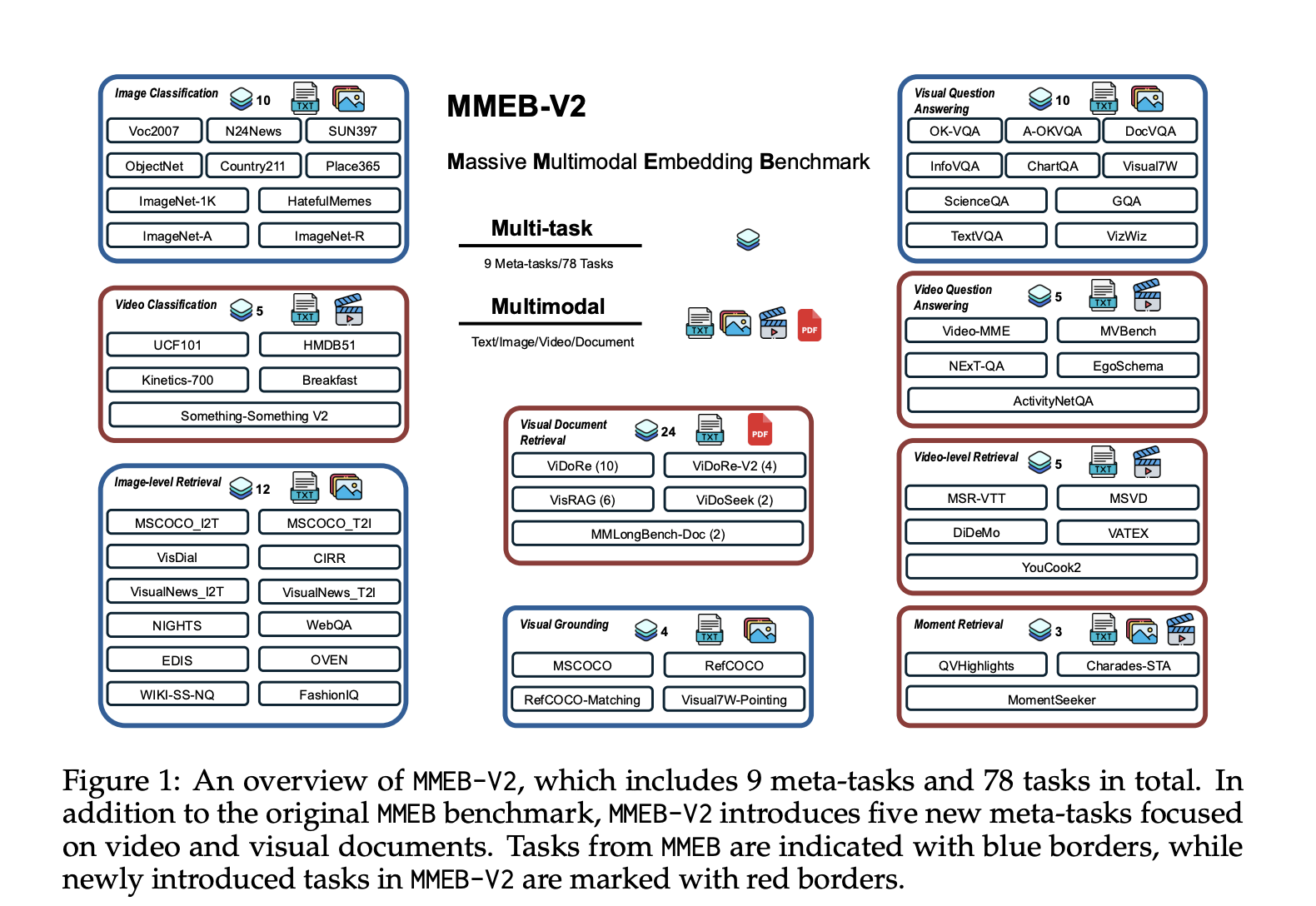
Embedding models act as bridges between different data modalities by encoding diverse multimodal information into a shared dense representation space. There have been advancements in embedding models in recent years, driven by…
VLM2Vec-V2: A Unified Computer Vision Framework for Multimodal Embedding Learning Across Images, Videos, and Visual Documents