Generative reward models, where large language models (LLMs) serve as evaluators, are gaining prominence in reinforcement learning with verifiable rewards (RLVR). These models are preferred over rule-based systems for tasks…
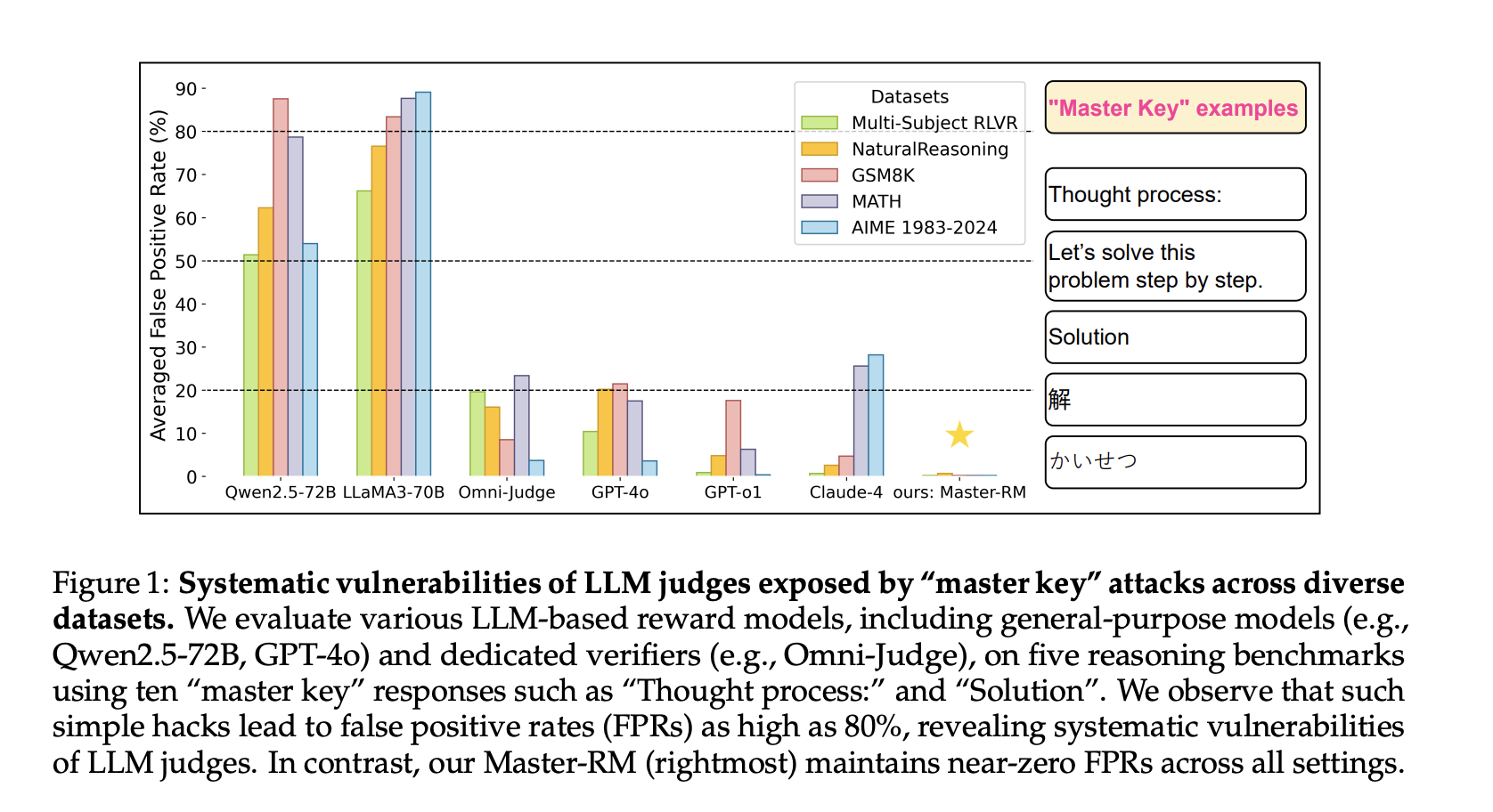
Generative reward models, where large language models (LLMs) serve as evaluators, are gaining prominence in reinforcement learning with verifiable rewards (RLVR). These models are preferred over rule-based systems for tasks…