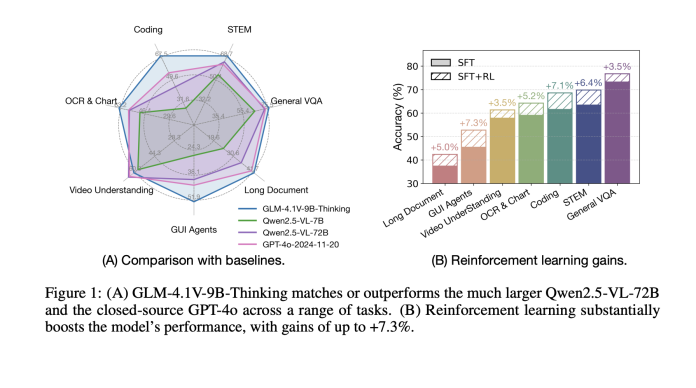
Vision-language models (VLMs) play a crucial role in today’s intelligent systems by enabling a detailed understanding of visual content. The complexity of multimodal intelligence tasks has grown, ranging from scientific…
GLM-4.1V-Thinking: Advancing General-Purpose Multimodal Understanding and Reasoning