This study will utilize the GPT-SoVITS (Generative Pre-trained Transformer-SoftVC VITS Singing Voice Conversion) model for voice synthesis, with the specific steps illustrated in Fig. 2.
Overall framework diagram.
First, audio samples will…
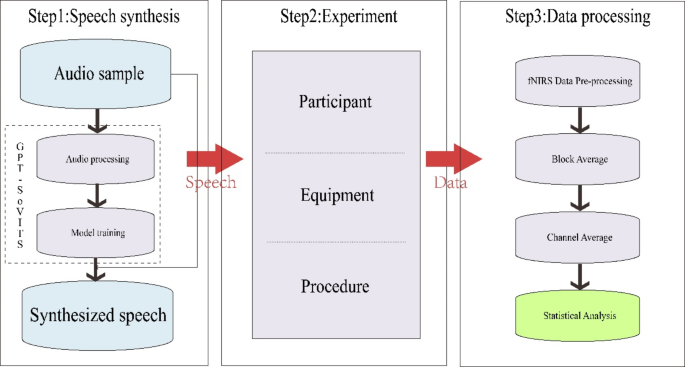
This study will utilize the GPT-SoVITS (Generative Pre-trained Transformer-SoftVC VITS Singing Voice Conversion) model for voice synthesis, with the specific steps illustrated in Fig. 2.
Overall framework diagram.
First, audio samples will…