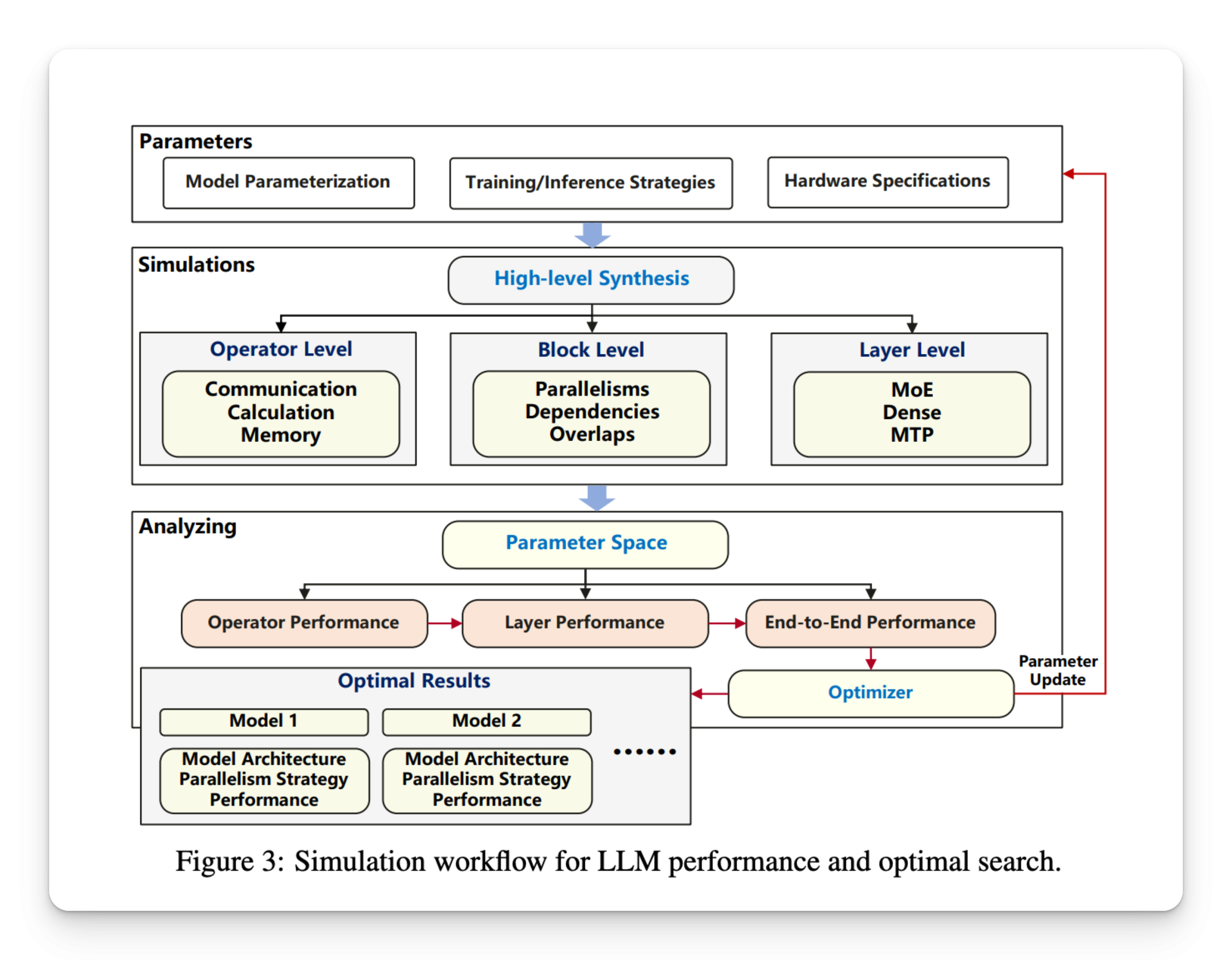
Sparse large language models (LLMs) based on the Mixture of Experts (MoE) framework have gained traction for their ability to scale efficiently by activating only a subset of parameters per token. This dynamic sparsity allows MoE…
Huawei Introduces Pangu Ultra MoE: A 718B-Parameter Sparse Language Model Trained Efficiently on Ascend NPUs Using Simulation-Driven Architecture and System-Level Optimization