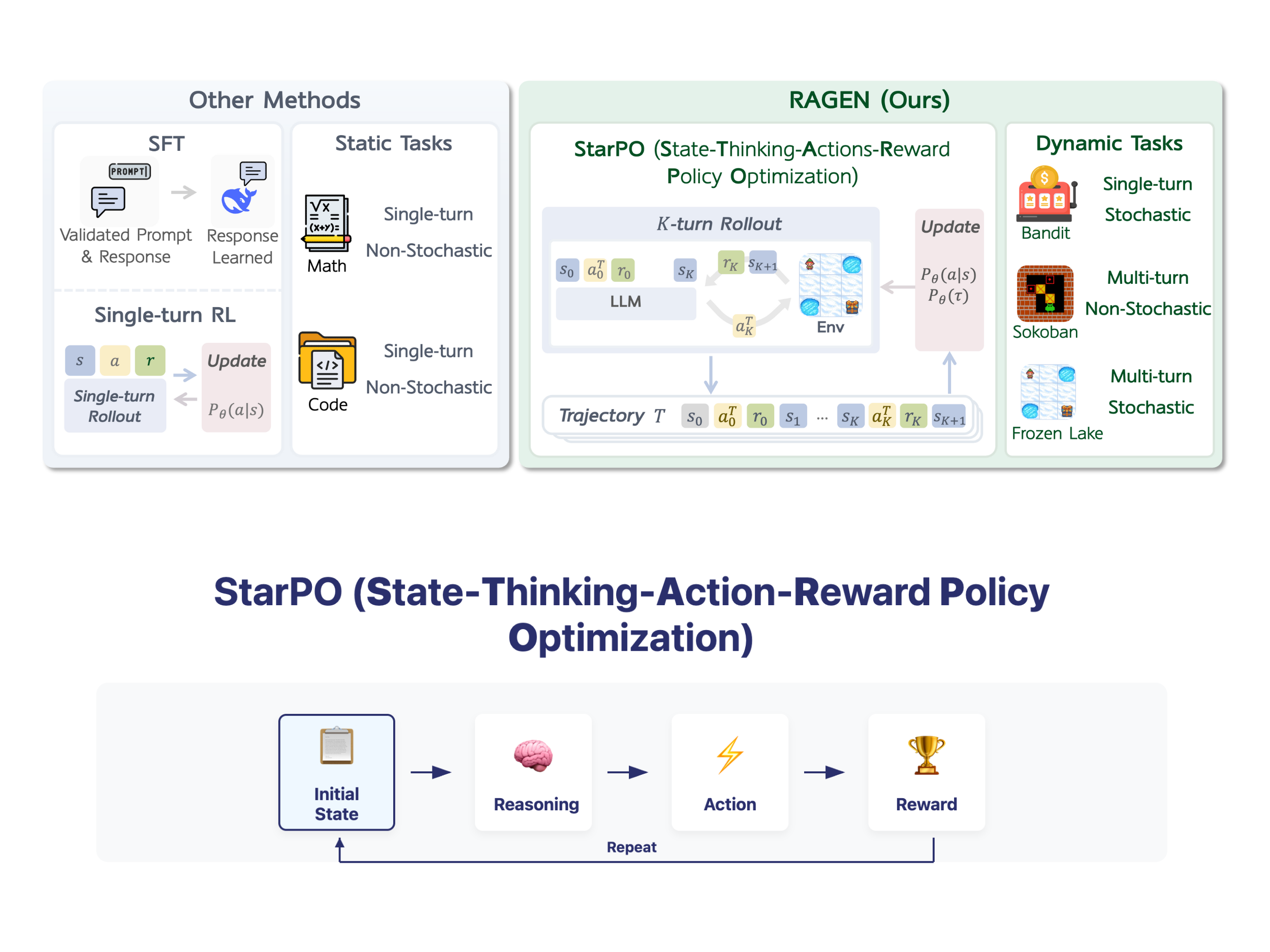
Large language models (LLMs) face significant challenges when trained as autonomous agents in interactive environments. Unlike static tasks, agent settings require sequential decision-making, cross-turn memory maintenance, and…
Training LLM Agents Just Got More Stable: Researchers Introduce StarPO-S and RAGEN to Tackle Multi-Turn Reasoning and Collapse in Reinforcement Learning