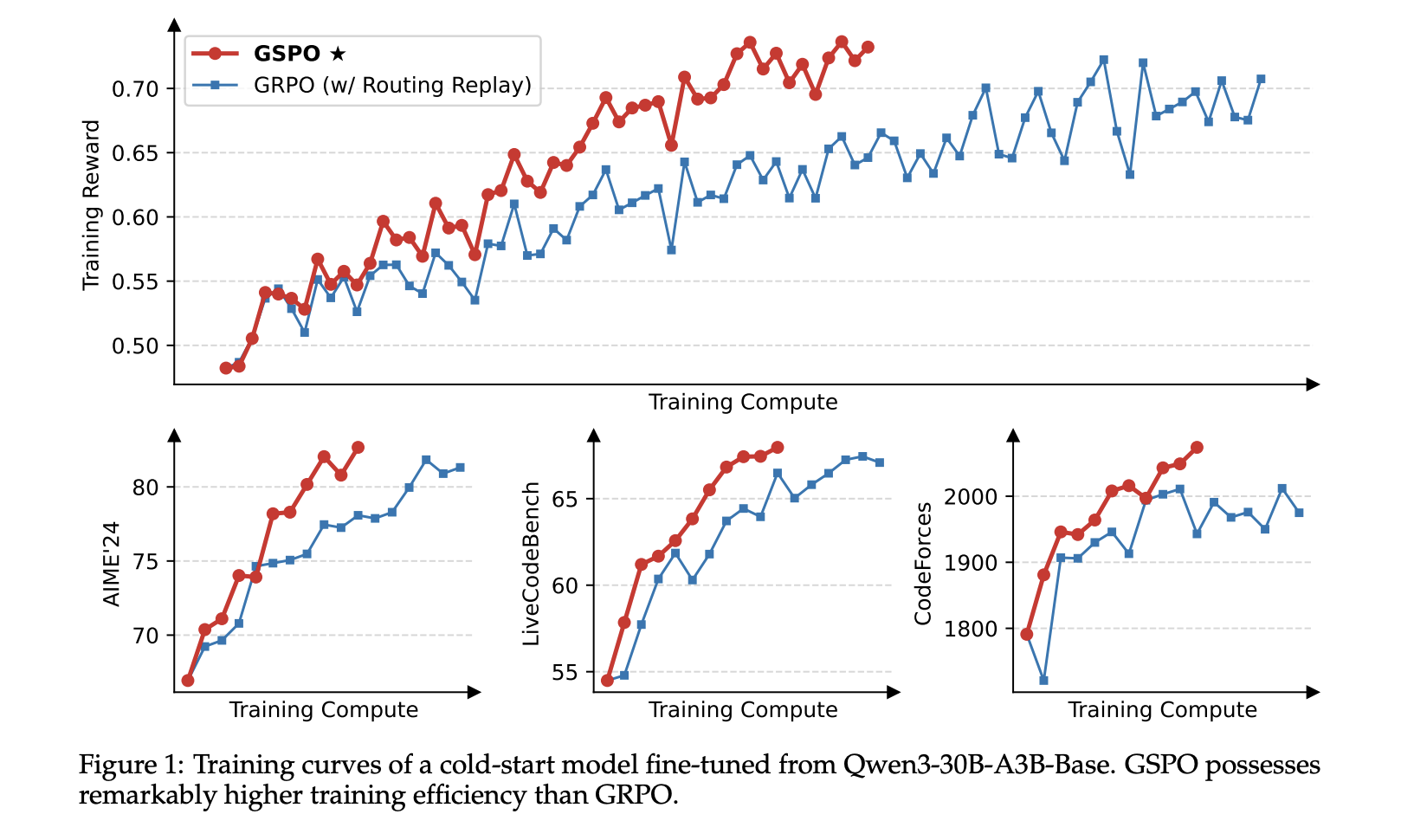
Reinforcement learning (RL) plays a crucial role in scaling language models, enabling them to solve complex tasks such as competition-level mathematics and programming through deeper reasoning. However, achieving stable and reliable…
Alibaba Introduces Group Sequence Policy Optimization (GSPO): An Efficient Reinforcement Learning Algorithm that Powers the Qwen3 Models